Introduction
|
This introduction talks about the work of the author and others, but without bibliographic references. Currently, it is just meant as background to better understand the technical documentation in the sections to follow. Maybe it could be developed into a more serious paper later. |
The overall motivation for the work on data catalogs for simulation is to make easier to develop and perform computer simulations in quite complex and data rich domains like building physics, transportation, and all kinds of urban infrastructure.
The Bigger Picture
A good part of computer science was and is driven by the motivation to make it easier to develop computer programs of all sorts. "Higher" programming languages were invented to make programs human readable and soon special constructs for functional programming (computation without side effects) and structured programming (computation without go to statements) were introduced to help programmers writing and understanding ever growing programs. Then, between 1962 and 1967, program language Simula was developed especially to deal with the challenges of simulating systems comprising of many different types of objects. This opened the door to more direct computer representations of real world objects, their attributes, relationships and behavior, ultimately leading to object-oriented software development that today is embodied in programming languages like Java, C++, Python, and graphical notations like the Unified Modeling Language (UML).
While these achievements had boosted the productivity of software developers, still the creation of correct, efficient and maintainable programs — including simulations — required a big deal of expert knowledge and experience. To overcome this bottleneck, starting in the 70s, so called 4th generation languages entered the stage. These languages were tailored to specific tasks like statistics ("S" 1976, "R" being its successor), database programming (SQL 1979), or simulation (MATLAB around 1979, Mathematica 1988, Modellica 1999) to name a few. By sacrificing generality, these special languages become more accessible to domain experts, not just trained software developers. To flatten the learning curve even more, formal graphical languages for special purposes were invented, e.g. Simulink for block diagram simulation models in 1984, Entity-Relationship-Diagrams for data modeling in 1976, UML for object-oriented systems design in the 1990s, or graphical languages to specify business and also scientific workflows around 2000.
This very short history on technologies for development of software in general, and simulations in particular, shall illuminate the tools at our disposal:
-
general purpose programming languages that combine structured, functional and object-oriented approaches to enable the creation of big, modular software systems, often called "programming in the large"
-
formal textual domain specific languages (DSLs) dedicated to solve specific tasks with ease
-
formal graphical DSLs.
Note that DSLs more tend to describe what shall be achieved by a computation instead of describing in detail, how to achieve it. Therefore, DSLs usually look more like a model than like an algorithm.
Now back to the task at hand.
Some domains deal with a few types of simple objects to be simulated. Take the building blocks of an electric circuit as an example. The algorithms to simulate these correctly and efficiently may be quite complex — the model elements usually can be described by very few parameters like resistance or capacity. More complex domains like (regenerative) energy systems or building physics deal with more complex objects to be simulated, e.g. PV modules or layered walls of buildings, often coming in different types and configurations, and dozens of possibly interdependent parameters.
Lessons Learned
The above problem of navigating huge parameter spaces and assembling complex simulation models popped up as the author worked on the diagram editor for INSEL, a simulation language and runtime environment developed for renewable energy systems simulation. To make existing catalogs on weather data, solar panels and inverter modules accessible to the modeler, special dialogs were added to the INSEL user interface that allowed browsing through the catalogs. Using this browsers, the modeler would choose a weather station, panel or inverter to parameterize a corresponding INSEL block. However, there are some severe disadvantages with this approach:
-
Data catalogs were stored in a proprietary data format on disk within the INSEL application distribution, meaning they could not used independently from INSEL by other interested parties (systems or users).
-
The catalogs have to be maintained by editing text files manually.
-
While INSEL modeler could browse the catalogs, searching and sorting were not supported.
-
Development of Java Swing UIs for the different kind of catalogs is time consuming as is their maintenance, e.g. if a catalog data format were to change.
-
Putting UIs to handle big amounts of data into a diagram editor is not very user friendly.
From 2013 to 2016, the simulation platform SimStadt was developed to make specific modeling and simulation workflows accessible to experts in urban planning and energy systems. Using INSEL and other simulators under the hood, the usage of 3D city data, provided as CityGML files, was a core requirement of this project.
To enable simulation of, say, the heating demand of a district, geometric building data had to be enriched with data on building physics and usage. To do so, existing informations about building physics and usage — often only available as informal typologies or tables — had to be provided to the SimStadt user on an abstract level, e.g. to choose between refurbishment scenarios. At the same time, concrete building configurations and parameter sets had to be injected into the simulation models to obtain the desired results.
Again, we implemented data catalogs to fulfill these requirements, but compared to the quite simple catalogs used in INSEL, the data models for building materials, window, wall and roof types as well as the typologies of buildings, households, usage patterns, and so on were more intricate. They had to be created iteratively in collaboration with domain experts. In this situation, manual coding data formats and access with a general programming language would have led to relatively long iteration cycles and high communication effort between programmer and domain expert. Instead, we decided to use a DSL for data modeling and use code generation whenever possible. Since SimStadt was developed within the Java eco-system we followed this standard approach:[1]
-
Developer and domain expert create a first version of the data model as XML Schema Definition (our DSL).
-
For plausibility checks use any standard XML editor to create example data conforming to the XSD.
-
With JAXB, the Java Architecture for XML Binding, Java code is generated to read our XML catalogs into Java objects that, in turn, can be accessed by SimStadt workflows to generate and parameterize simulations.
-
If required, developer and domain expert go back to step one to refine data model and catalog data.
After the data model for building physics catalogs had matured, we developed an extra application for convenient creation and maintenance of building physics data catalogs separate from SimStadt. It was developed in Java with a user interface written in JavaFX and was well received by domain expert users.
However, as a different catalog — this time for building usages — had to be created, it was quite difficult to reuse the XML schema and application code from the building physics catalog: The usage catalog data model was "pressed" into a form similar to the building physics catalog data model, and the UI code was "over-engineered" to accommodate both catalog’s requirements.
Low-Code-Development of Data Catalogs
From INSEL and SimStadt we learned, that manual and automatic construction and parameterization of complex simulation models with many types of interrelated objects should be supported be the means of domain specific data catalogs.
Close collaboration with domain experts in designing and implementing these catalogs in short development cycles is desirable.
Data catalogs and the software for their creation, maintenance and deployment should be independent of any specific simulation software, (a) to be reusable and (b) not to overload simulation applications.
In SimStadt, catalog development was partly facilitated by a textual DSL for data modeling (XML schema language) and automatic generation of Java code from it. On the other hand, user interfaces and generation and parameterization of simulations from templates within SimStadt workflows had still to be coded manually hindering the routinely creation of new catalogs.
Now, in 2020, several developments in different projects provide an opportunity to re-think the topic of data catalogs for simulations, namely:
-
Plans for a new Urban Simulation Platform at Concordia University, Montreal.
-
New implementation of INSEL user interface based on the Eclipse application framework and Eclipse-Sirius diagram editors.
-
Enhancement of existing building physics and usage catalogs from SimStadt and their adaptation to new regions.
-
Development of a new comprehensive catalog of electric systems components to be used in SimStadt as well as in Concordia’s Urban Simulation Platform.
In what follows, the new technology stack used to implement (4) is documented in detail. It uses four technologies to replace manual coding by code generation from models:
-
Ecore to model the catalog’s data and generate Java classes and persistence layer from it.
-
EMF Forms for modeling and generating tables, forms and buttons to create, read, update, and delete data (CRUD).
-
E4, the Eclipse way of modeling the application user interface itself, e.g. the placement and behavior of views, editors, toolbars, menus, and more.
-
A template engine called Handlebars to generate fully parameterized simulation models from textual templates without programming.
The new technology stack is rooted in the Eclipse application framework and eco-system.[2] Its main advantage is the possibility to implement CRUD applications like data catalogs and their underlying data models with no or very view lines of handwritten code (low-code-development).
Plans are to use the same approach also for implementation of (3). Since task (2) and maybe (1) will use Eclipse, too, close integration of data catalogs and simulation environments seems feasible. E.g., a user could drag an electric system component from a catalog onto an INSEL block for parametrization.
The Eclipse application framework offers:
-
OSGI plug-in mechanism and UI framework for integrating applications and services
-
E4 application model to declaratively describe user interface’s structure
-
General notion of project with specific file types, help system, preferences etc.
-
IDE support for important general purpose languages like Java, Python, Ruby, C, Fortran, C++
-
Support for creating textual and graphical DSLs (XText, Sirius)
-
Industry proven DSLs and code generators for data models and form based UIs via the Eclipse Modeling Framework (EMF) providing:
-
Ecore for model driven generation of Java classes and persistence layers for XML or data bases
-
EMF Forms for describing and generating form based UIs
-
Mechanisms to adapt or extend data models and forms to special needs (e.g., we added quantities — that is numbers with units — to Ecore and EMF Forms, a feature very important for data catalogs)
-
-
Rich open source eco-system with lots of plugins and projects important for an urban simulation platform:
-
model server for distributed access and work on Ecore models, including model comparison and migration (CDO, EMFCompare)
-
GIS: storage, processing, and visualization of geographical data (list of projects under the umbrella LocationTech, e.g. user-friendly desktop internet GIS uDig)
-
workbench for traffic simulation (SUMO)
-
spatial multi-agent-simulation (GAMA-Platform)
-
scientific workflows (Triquetrum)
-
visualizations (Nebula)
-
machine learning (deeplearning4j)
-
45+ projects in the area of IoT
-
…
-
As always, all that glitters is not gold. When we go through the details below, some bugs and inconsistencies, typical for open source projects of this age and size, have to be addressed.
How to Implement Data Catalogs with Eclipse
To build a new data catalog from scratch, we first have to understand some basics about Eclipse, and then install the correct Eclipse package. Thereafter, we can model our data with Ecore considering some best practices, followed by the generation of Java classes and user interface (UI). We, then, will add some plug-ins to "pimp" our Eclipse installation, (a) to enable deployment of data catalog applications, and (b) to add units and quantities to the mix. Some hints on special modeling problems and versioning data catalogs conclude this how-to guide.
Eclipse Basics
Eclipse was originally developed by IBM and became Open Source in 2001. It is best known for its Integrated Development Environments (Eclipse IDEs), not only for Java, but also for C++, Python and many other programming languages. These IDEs are created on top of the Eclipse Rich Client Platform (Eclipse RCP), an application framework and plug-in system based on Java and OSGi. Eclipse RCP is foundation of a plethora of general-purpose applications, too.
First time users of Eclipse better understand the following concepts.
An Eclipse package is an Eclipse distribution dedicated to a specific type of task.[3] A list of packages is available at eclipse.org. Beside others it contains Eclipse IDE for Java Developers, Eclipse IDE for Scientific Computing, and the package we will use: Eclipse Modeling Tools. Note that third parties offer many other packages, e.g. GAMA for multi-agent-simulation or Obeo Designer Community for creating Sirius diagram editors, both noted above.
|
Several Eclipse packages can be installed side by side, even different releases of the same package. Multiple Eclipse installations can run at the same time, each on its own workspace (see below). |
An installed Eclipse package consists of a runtime core and a bunch of additional plug-ins. Technically, a plug-in is just a special kind of Java archive (JAR file) that uses and can be used by other plug-ins with regard to OSGi specifications. Groups of plug-ins that belong together are called a feature.
Often, a user will add plug-ins or features to an Eclipse installation to add new capabilities.
E.g. writing this documentation within my Eclipse IDE is facilitated by the plug-in Asciidoctor Editor.
Plug-ins can easily be installed via main menu command Help → Eclipse Marketplace… or Help → Install New Software….
Some plug-ins may be self-made like our plug-in de.hftstuttgart.units that enables Ecore to deal with quantities.
These may be provided via Git or as download and have to be added to an Eclipse installation manually.
Git is the industry standard for collaborative work on, and versioning of, source code and any other kind of textual data. Collaborative development of data catalogs benefits massively from using Git, and Git support is built into Eclipse Modeling Tools, the Eclipse package we will use. However, if Eclipse needs to connect to a Git server that uses SSH protocol (not HTTPS with password), access configuration is more involved and may be dependent on your operating system.
Some users, anyway, prefer to use Git from the command line or with one of the client application listed here, e.g. TortoiseGit for Windows.
While it is required to get Git working at some point, we won’t refer to it in this document and, for now, do not cover the installation of Git on your machine or configuration of Git in Eclipse.
When you start a new Eclipse installation for the first time, you are asked to designate a new directory in your file system to store an Eclipse workspace.
Eclipse is always running with exact one workspace open.
As the name implies, a workspace stores everything needed in a given context of work, that is a set of related projects the user is working on as well as meta-data like preference settings, the current status of projects, to do lists, and more.
In case a user wants to work in different contexts, e.g. on different tasks, command File → Switch Workspace allows to create additional workspaces and to switch between them.
|
Any plug-in from the original Eclipse package or installed by the user later will be copied into the Eclipse installation directory, not in any workspace. Configuration and current state of plug-ins, on the other hand, are stored in workspaces. |
An Eclipse project is a technical term for a directory that often contains:
-
files of specific types for source code, scripts, XML files or other data
-
build settings, configurations
-
dependency definitions (remember the dependencies between plug-ins above?)
-
other Eclipse projects.
Depending on the plug-ins installed, File → New → Project… offers many different types of projects that the user can choose from, e.g. Java projects to create Java programs, Ecore modeling projects, or general projects, that simple hold some arbitrary files.[4]
|
Files that do not belong to a project are invisible for Eclipse! |
The projects belonging to a workspace can either be directly stored within the workspace as sub-directories (the default offered to the user when creating a new project), or linked from it, that is the workspace just holds a link to the project directory that lives somewhere in the file system outside of the workspace. Linking allows to work with the same projects in different workspaces.
While it sometimes makes sense to share or exchange workspaces between users,[5], I do not recommend this for now.
Projects, on the other hand, are shared between users most of the time, usually via Git.
In general, I would suggest to store Eclipse projects outside workspaces at dedicated locations in the user’s file system.
That way, we can follow the convention that local Git repositories should all be located under
<userhome>/git.
Setup Eclipse Modeling Tools
As a Java IDE, Eclipse runs on 64-bit versions of Windows, Linux, and macOS and requires an according Java Development Kit (JDK), version 1.8 (aka version 8) or higher, to be installed on your machine.
If no such JDK already exists, please download version 11 of OpenJDK for your operating system from AdoptOpenJDK.
[6]
Choose HotSpot as Java Virtual Machine.
Installation process is straight forward, but you can also find links to exhaustive instructions for your operating system. Note that different versions of Java can peacefully coexist.
New Java versions appear every six months, so the actual version at the time of writing is 14. Since we stick with an older Eclipse version (see below), install version 11 as advertised! Also, this one is the latest LTE version (long time support).
Now its time to download and install the correct Eclipse package.
Please go to Eclipse download page for packages.
On top of this page you may see "Try the Eclipse Installer" or similar.
We won’t follow this advice, since it is not suited for our use-case. We won’t either download the most recent package because releases after 2019-12 come with a bug that prevents the user from editing data in table cells within the generated UI.
|
Download version 2019-12 (4.14) only!
Due to a bug in recent versions, make sure not to download the actual version, but the older version 2019-12 (4.14)! |
To do so, click the link depicted by the red arrow below.
A similar download page for all the packages appears, but this time for version 2019-12. Now look for package Eclipse Modeling Tools and follow the link for your operating system on the right:

Finally, you can click on Download and wait for the 400 something MB package to arrive.
|
Depending on the operating system, several security dialogs have to be acknowledged during installation and first launch of Eclipse. |
The downloaded installation file contains the application simply named Eclipse ready to be copied into Applications on macOS or be installed in Programs on Windows.
Since you may add other Eclipse packages later, I suggest to rename the application to something more significant like EclipseModeling.
After installation has finished launch Eclipse for the first time and you will see the dialog for choosing a new empty directory as its workspace pop up.
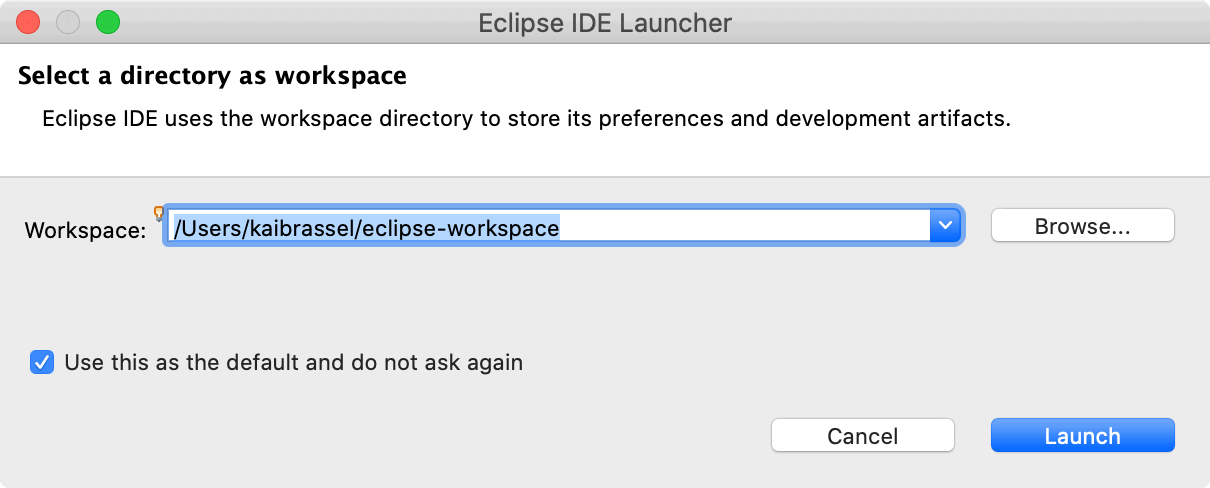
Again, more workspaces might come into existence later, so replace the proposed generic directory path and name with a more specific one, e.g.EclipseModelingWS.
The Eclipse main window appears with a Welcome Screen open.
It contains links to exhaustive documentation on concept, features and usage of Eclipse that might be of interest later, especially:
-
Overview
-
Workbench basics
-
Concepts: features, resources, perspectives, views, editors
-
Opening perspectives and views
-
Installing new software manually
-
-
Team support with Git
-
-
Learn how to use the Ecore diagram editor
-
Launch the Eclipse Marketplace
For now, you can dismiss the welcome screen. It can be opened anytime by executing Help → Welcome
Modeling Data Catalogs for Simulation with Ecore
Now you should see the initial layout of Eclipse with Model Explorer and Outline on the left and a big empty editing area with Properties view below to the right.
Since we will use Ecore diagrams for data modeling, create your first Ecore modeling project now:
-
Execute
File → New → Ecore Modeling Projectfrom main menu — notModeling Project! -
Name it
project.firstand clickNext > -
Uncheck
Use Default Locationso that the new project is not stored in the workspace, but a different directory you choose, then clickNext > -
Provide
datacatalogas main Java package name and clickFinish.
Eclipse should look like below with an new empty graphical Ecore diagram editor opened.
The diagram is automatically named datacatalog after the package name for the Java classes that will be generated from it (provided above).
The Model Explorer shows the contents of the new Ecore modeling project.
To get your feet wet, do this:
-
Drag a Class from the palette on the right onto the editor’s canvas: it will materialize as a rectangle labeled
NewEClass1. -
The class symbol was selected initially, so you can see its attributes in the Properties view.
-
In there replace
NewEClass1byEnergyComponentsCatalogto rename the class. -
Click anywhere on the canvas and notice that the class symbol is deselected and the toolbar at the top adapts accordingly.
-
In the toolbar change
100%to75%to scale the diagram -
Execute
File → Saveand model and diagram are saved. -
Close diagram editor
datacatalogby closing its tab. -
Reopen saved diagram by double click on entry
datacatalogin the Model Explorer.
Technically, everything is in place now to begin modeling the data that the projected catalog shall contain. Except … understanding the basics of object-oriented modeling would be helpful. This is why developers should support domain experts at this stage.
Ecore diagrams are simplified UML class diagrams. Here some resources on what this is all about:
|
Beginners are strongly encouraged to read the first two resources. The first one contains a gentle introduction, especially suited for domain experts. The second one can also serve as reference. |
We will touch central object oriented concepts Class, Object, Attribute, Association, Composition, and Multiplicity in an example below, but work through above sources to get a deeper understanding and enhance your modeling skills.
Note that the sources differentiate between conceptual and detailed models. In principle we go for detailed models, since only these contain enough information to generate code. Having said this, it is usually a good idea to have two or three conceptual iterations at a white board to agree on the broad approach before going too much into detail. But even if one starts with Ecore models right away, these also can be adapted any time to follow a new train of thought.
See here the essential and typical structure of a data catalog in a class diagram. Instead of artificial example classes like Foo and Bar it shows classes from an existing catalog, albeit in a very condensed form.

The diagram models four types of technical components whose data shall be stored in the catalog for later use, e.g. for parameterization of simulation models: Boiler, CombinedHeatPower, SolarPanel, and Inverter.
The catalog itself is represented by class EnergyComponentsCatalog. Unlike dozens, hundreds, or even thousands of objects to be cataloged — Boilers, Inverters etc. — there will be just exactly one catalog object in the data representing the catalog itself. Its "singularity" is not visible in the class diagram, but an Ecore convention requires that all objects must form a composition hierarchy with only one root object.
If, in the domain, one object is composed of others, this is expressed by a special kind of association called composition.
Compositions are depicted as a link with a diamond shape attached to the containing object. In the Boiler case said link translates to: The EnergyComponentsCatalog contains — or is composed of — zero or more (0..*) boiler objects stored in a list named boilers.
|
Note that class names — despite the fact that they model a set of similar objects — are always written in singular! They are written in Camel case notation starting with an upper case letter. Associations and attributes are written the same way, but starting with a lower case letter. Names for list-like associations and attributes usually are written in plural form. |
Besides composition of objects, the model above shows another completely different kind of hierarchy: the inheritance hierarchy between classes. Whenever classes of objects share the same attributes or associations, we don’t like to repeat ourselves by adding that attribute or relation to all classes again and again. Instead, we create a super class to define common attributes and associations and connect it to sub classes that will automatically inherit all the features of their super class.
In our example above, common to all four energy components are attributes modelName and revisionYear, thus these are modeled by class EnergyComponent that is directly or indirectly a super class of Boiler, CombinedHeatPower, SolarPanel, and Inverter.
Similar, Boiler and CombinedHeatPower share attribute installedThermalPower factored out by class ChemicalEnergyDevice.
You probably noticed a fifth type of objects contained in the catalog, namely Manufacturer objects stored in list manufactureres.
How come? Ok, here is the story:
Observe in our data model, reference producedBy points from EnergyComponent to Manufacturer making it uni-directional reference.
One can simply query the manufacturer of a product, but not so the other way around.
With a bi-directional reference both queries would be available.
Observe also the annotations 0..* and 1..1 near class Manufacturer.
These are multiplicities of associations: An EnergyComponentsCatalog contains zero, one, or many objects of class Manufacturer and an EnergyComponent must reference exactly one manufacturer — not less, not more.

To recapitulate: Our example data catalog already exhibits all four types of relations provided by Ecore.
You find these in the Ecore editor’s palette shown here.
To create a relation between a sub class and a super class use tool SuperType.
Use the other tools to create an association between classes, may it be a simple (uni-directional) reference, a bi-directional reference, or a composition.
Obviously, attributes are central in data modeling.
Create one by dragging it from the palette onto our one and only class so far: EnergyComponentsCatalog.
The class symbol will turn red to indicate an error.
Hover with the mouse pointer over the new attribute and a tooltip with a more or less helpful error message will appear.
The error is caused in that no data type was set for the new attribute.
Data types for attributes can be integer or float numbers, strings, dates, booleans, and more.
To get rid of the error:
-
If not already selected, select new attribute by clicking at it in the editor.
-
In view Properties find
ETypeand click button…to see a quite long list of available data types. -
Choose
EString [java.lang:String]from the list and the error is gone.

Change the attribute’s name to author and the class should look like shown here.
Most data types to choose from begin with an E like in Ecore. These are simply Ecore enabled variants of the respective Java types, thus, choose EInt for an int, EFloat for a 32 bit floating point number, EDouble for a 64 bit one, and so on.
Ecore allows to introduce new data types. We employ this feature later to enable data model with physical units and quantities.
There exists one other means to define the values an attribute can take, namely enumerations of distinct names. Take Monday, Tuesday, Wednesday, … as a typical example for representing weekdays.
In our example data model you’ll find one Enumeration named BoilerType with values LowTemperature and Condensing.
The next section deals with generation of Java code from data models. To have more to play with, please implement our example model in Ecore now.
To do this, there is one more thing to know about classes: the difference between ordinary classes and abstract classes. 'Ordinary class' doesn’t sound nice, therefore, classes that are not abstract are called concrete classes. Our example diagram depicts abstract classes with letter A while concrete classes are labeled with C. You add abstract classes to a model with a special palette tool shown here.
The thing is: Objects can be created for concrete classes only!
In our example, it makes no sense to create an object from class EnergyComponent, because there is not such a thing like an energy component per se. Therefore, this class is abstract. It is true that an inverter is an energy component, thus inheriting all its features, but it was created as Inverter, not as EnergyComponent.
Super classes will be abstract most of the time. So my advice is: Model a super class as abstract class unless you convince yourself that there are real objects in the domain that belong to the super class but, at the same time, do not belong to any of its sub classes.
In the Ecore editor properties view, you can specify if a class is abstract or not, simply by toggling check box Abstract.
|
An exhaustive user manual for Ecore diagram editor is available. Execute |
|
If Ecore models get bigger, you may find it more convenient to work with a form based UI instead of, or in addition to, the diagram editor.
Open this kind of editor via command |
Generation of Java Code from Data Model
TBD
Let us bring the data model to life, that is, generate program code from it that can be used to create, edit and delete concrete data objects of the classes modeled in computers.
I would like to tell you that this is done with one click but, actually, you need two or three:
-
Make sure, all files are saved by ..
-
Open the context menu of Ecore editor showing the model and perform
Gerenerate → Model Code -
Gerenerate → Edit Code(Do not executeGerenerate →Editor Code— we do not need this).
Creation — Recreation
Custom code marked with @generated NOT in de.hftstuttgart.energycomponents.provider in project de.hftstuttgart.energycomponents.edit
Generation and Tweaking of UI
If there are many types of entities, their tables may be ordered hierarchical in the user interface to simplify user access. Probably, this hierarchy will be different from aggregation and inheritance hierarchies present in the Ecore model. We get to this later when we create a UI model for the data catalog.
Table columns sequence and width.
for creating custom UI labels:
-
ExponentialFunctionItemProvider.java -
LinearFunctionItemProvider.java -
TableFunctionItemProvider.java
Run and Deploy the Demo Data Catalog Application
TBD
We are going to create a complete Eclipse desktop application from generated code. We also want to deploy this application for Linux, macOS and Windows operating systems. Eclipse offers several approaches for compiling and deploying such an application, traditionally with Ant scripts.
Creation and maintenance of these scripts turned out to be tedious and error prone. For quite some years now, the proposed — and mostly supported — method for building Eclipse applications is to use Maven build system, more specifically, a couple of Maven plug-ins, subsumed under the name Tycho.
Many Eclipse platforms have Maven support M2Eclipse already built in, not so our Eclipse Modeling Tools. But don’t worry: Installation of required Eclipse feature is easy and straight forward. And, by the way, you will acquire the indispensable skill of how to install new plug-ins/features to Eclipse.
First, tell your Eclipse installation where to look for the new software.
Execute Help → Install new Software… to invoke dialog Available Software and press Add….
Sub-dialog Add Repository pops up.
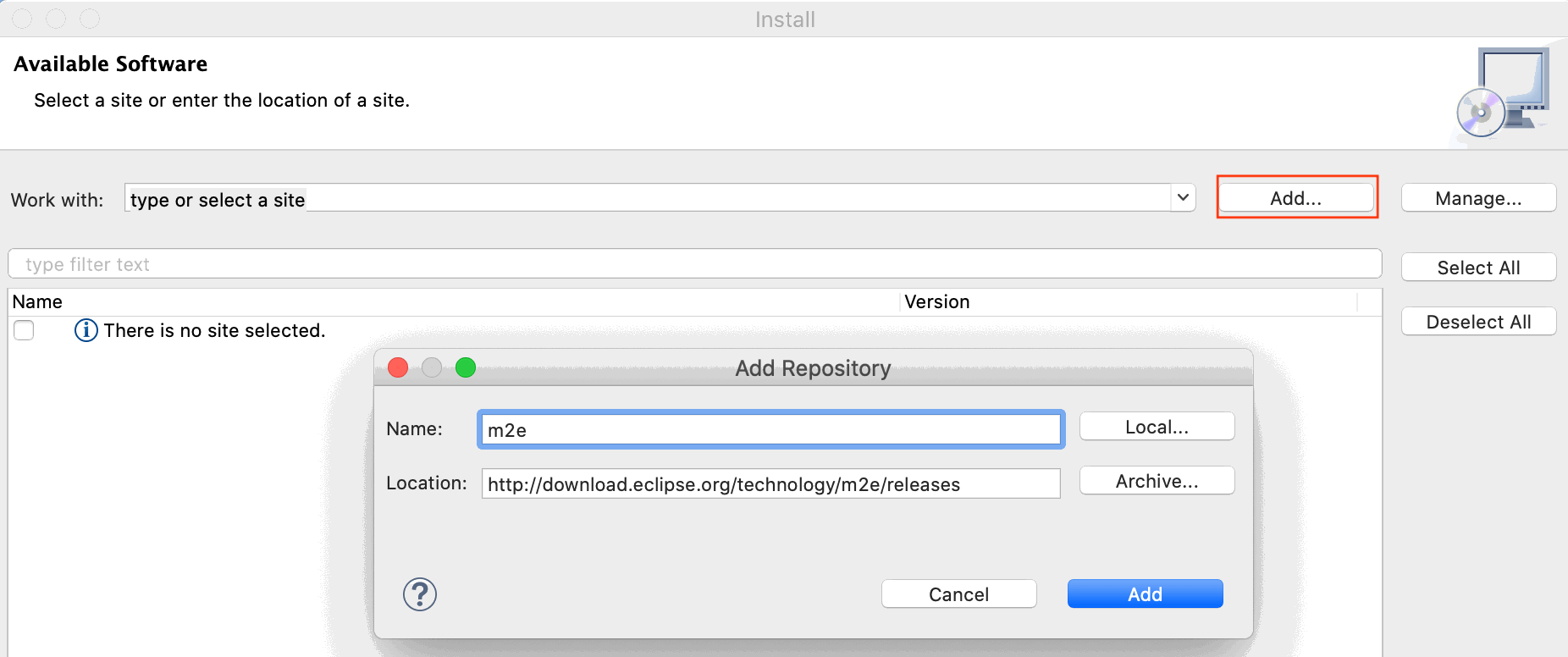
In there provide m2e as name and
http://download.eclipse.org/technology/m2e/releases
as location.
After confirmation with Add, Eclipse now looks up the site for available software.
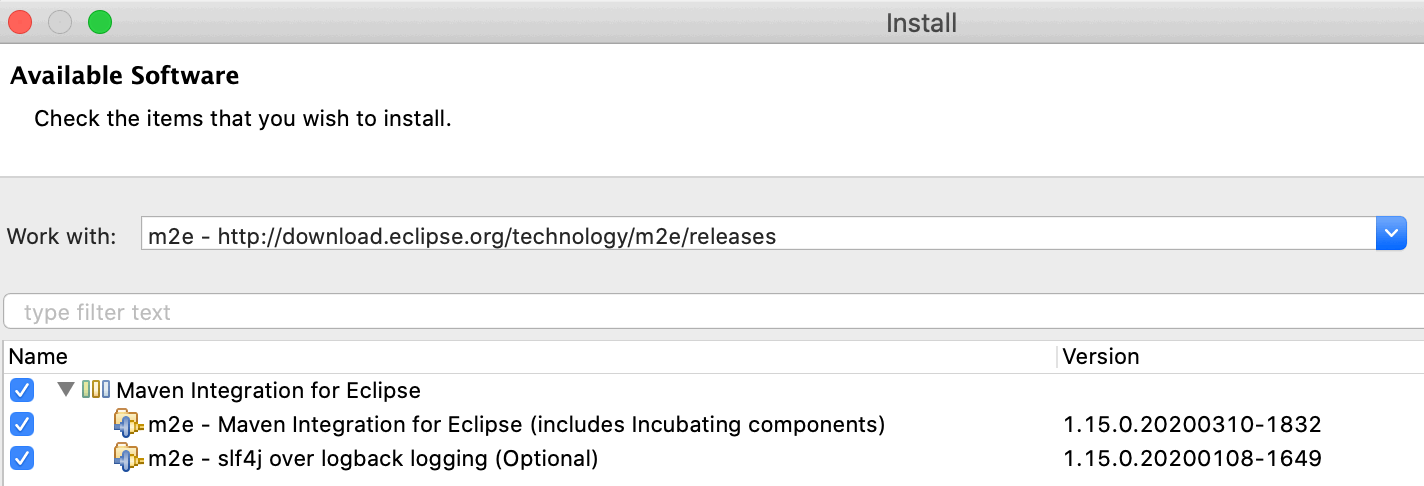
Check the items to install like shown above and confirm all following questions about licenses and security concerns.
After download is complete — it can take a few minutes — restart Eclipse.
Verify that Maven version 3.6.3 or above is now installed in Window → Preferences… (or Eclipse → Preferences… on macOS) under Maven → Installations.

TBD
Add Units to the Mix
TBD
As mentioned earlier, data catalogs for simulations should be able to represent quantities, not just bare integer and real numbers.
using Indrya, the reference implementation for Units of Measurement in Java (JSR 385)
To this end, the author has created two Eclipse plug-in projects providing this feature to be used by Ecore and EMF Forms.
Third-party libraries like Indrya, usually, are not distributed as plug-ins, but Tycho can wrap them automatically as OSGi plug-ins that can added directly to our application.
Another plug-in, created by the author connects the Ecore and Indrya. We will compile it from source code, simply by importing the projects.
-
Copy to file system …
-
Import project but not copying it in the workspace (just linking)
Ecore Solutions for Specific Modeling Problems
-
How to Represent Parameterized Functions
TBD
-
How to Model Derived References and Attributes
TBD
We haven’t used derived references or attributes by now. But if one has to implement some by providing a getter, it is necessary to return an unmodifiable list like BasicEList.UnmodifiableEList or EcoreUtil.unmodifiableList(…) instead of EList as described here: https://www.ntnu.no/wiki/plugins/servlet/mobile?contentId=112269388#content/view/112269388 .