Geo (PREMIUM SELF)
Geo is the solution for widely distributed development teams and for providing a warm-standby as part of a disaster recovery strategy.
Overview
WARNING: Geo undergoes significant changes from release to release. Upgrades are supported and documented, but you should ensure that you're using the right version of the documentation for your installation.
Fetching large repositories can take a long time for teams located far from a single GitLab instance.
Geo provides local, read-only sites of your GitLab instances. This can reduce the time it takes to clone and fetch large repositories, speeding up development.
For a video introduction to Geo, see Introduction to GitLab Geo - GitLab Features.
To make sure you're using the right version of the documentation, go to the Geo page on GitLab.com and choose the appropriate release from the Switch branch/tag dropdown list. For example, v13.7.6-ee.
Geo uses a set of defined terms that are described in the Geo Glossary. Be sure to familiarize yourself with those terms.
Use cases
Implementing Geo provides the following benefits:
- Reduce from minutes to seconds the time taken for your distributed developers to clone and fetch large repositories and projects.
- Enable all of your developers to contribute ideas and work in parallel, no matter where they are.
- Balance the read-only load between your primary and secondary sites.
In addition, it:
- Can be used for cloning and fetching projects, in addition to reading any data available in the GitLab web interface (see limitations).
- Overcomes slow connections between distant offices, saving time by improving speed for distributed teams.
- Helps reducing the loading time for automated tasks, custom integrations, and internal workflows.
- Can quickly fail over to a secondary site in a disaster recovery scenario.
- Allows planned failover to a secondary site.
Geo provides:
- Read-only secondary sites: Maintain one primary GitLab site while still enabling read-only secondary sites for each of your distributed teams.
- Authentication system hooks: Secondary sites receive all authentication data (like user accounts and logins) from the primary instance.
- An intuitive UI: Secondary sites use the same web interface your team has grown accustomed to. In addition, there are visual notifications that block write operations and make it clear that a user is on a secondary sites.
Gitaly Cluster
Geo should not be confused with Gitaly Cluster. For more information about the difference between Geo and Gitaly Cluster, see Comparison to Geo.
How it works
Your Geo instance can be used for cloning and fetching projects, in addition to reading any data. This makes working with large repositories over large distances much faster.
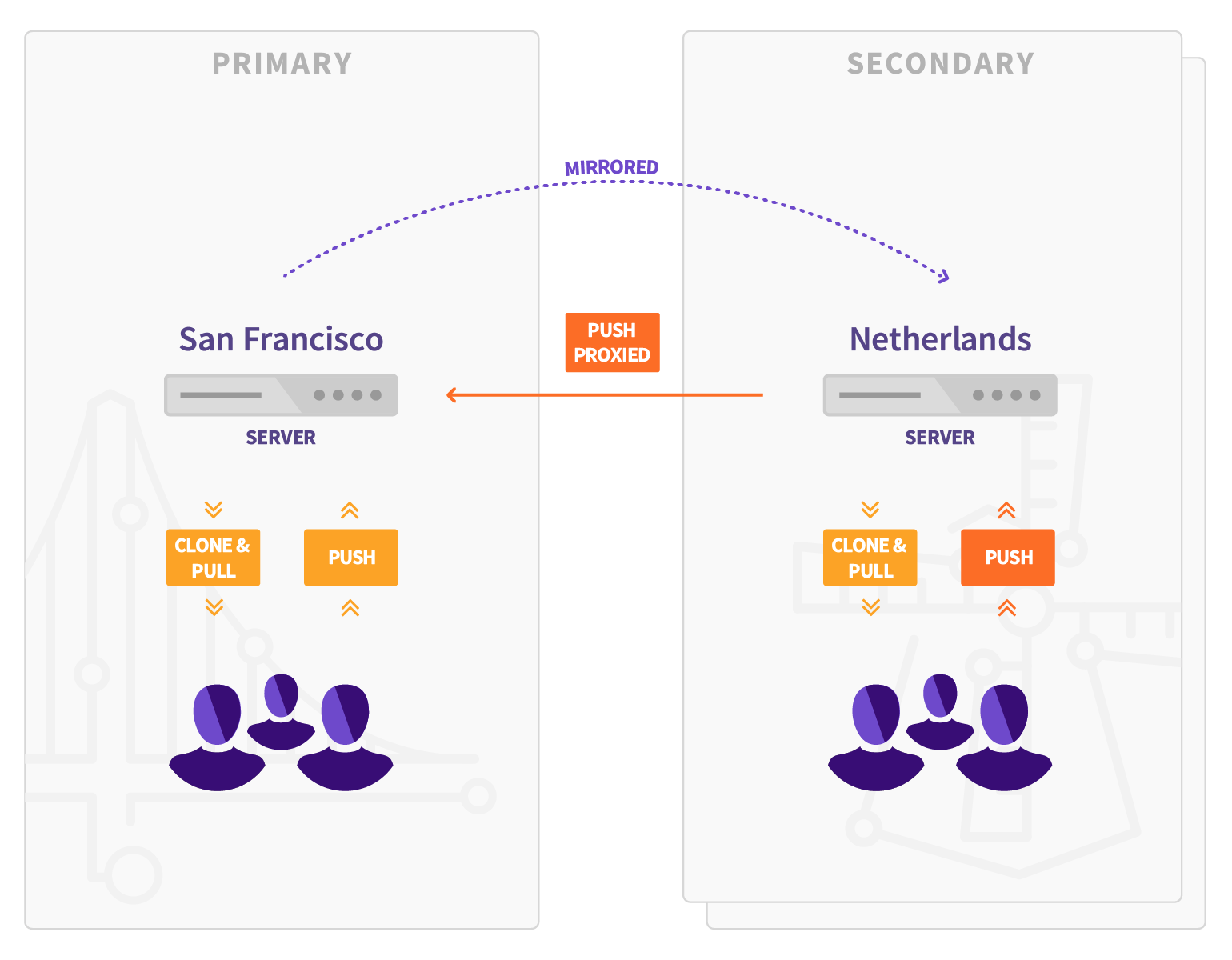
When Geo is enabled, the:
- Original instance is known as the primary site.
- Replicated read-only sites are known as secondary sites.
Keep in mind that:
-
Secondary sites talk to the primary site to:
- Get user data for logins (API).
- Replicate repositories, LFS Objects, and Attachments (HTTPS + JWT).
- The primary site doesn't talk to secondary sites to notify for changes (API).
- You can push directly to a secondary site (for both HTTP and SSH, including Git LFS).
- There are limitations when using Geo.
Architecture
The following diagram illustrates the underlying architecture of Geo.
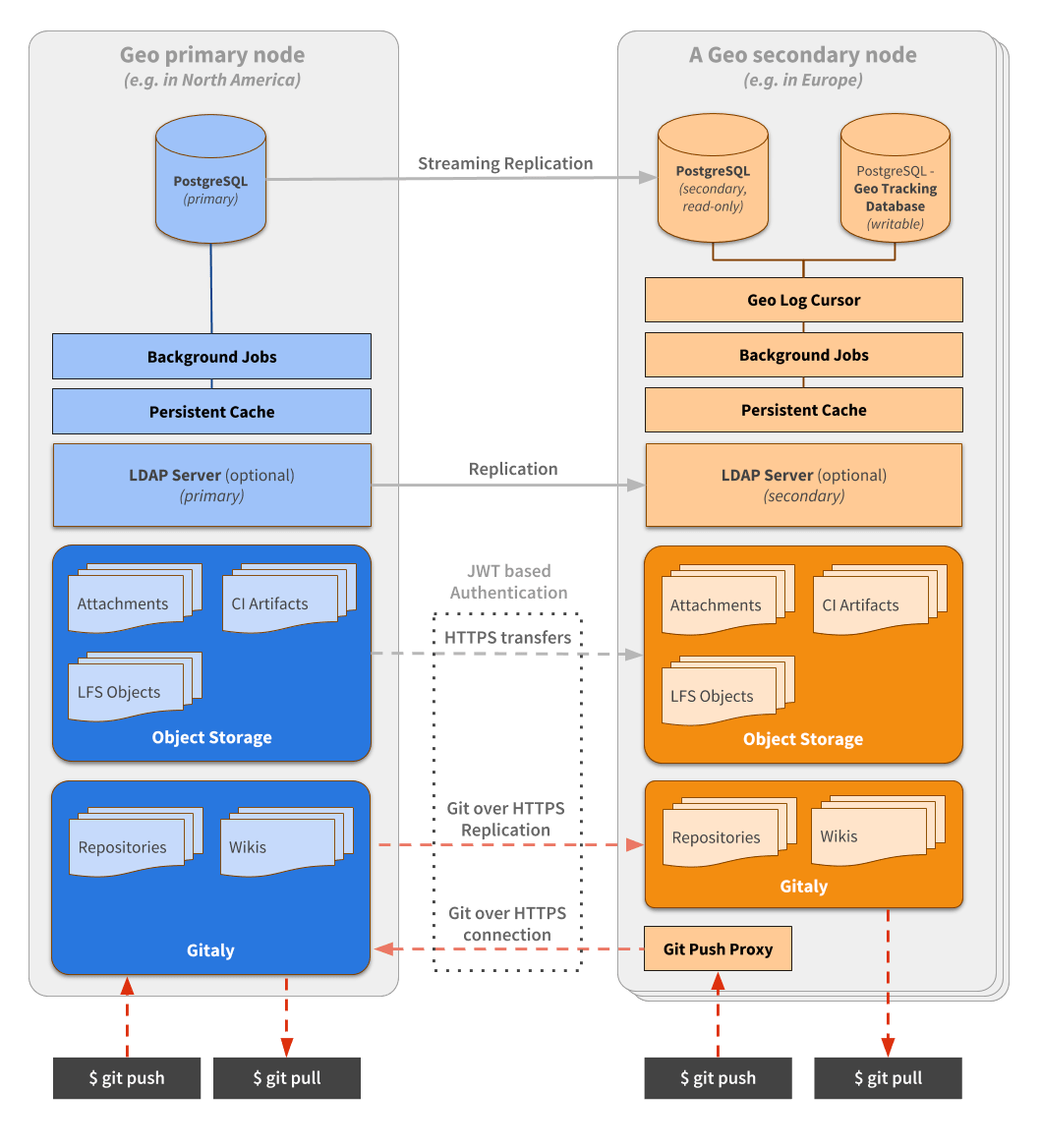
In this diagram:
- There is the primary site and the details of one secondary site.
- Writes to the database can only be performed on the primary site. A secondary site receives database updates via PostgreSQL streaming replication.
- If present, the LDAP server should be configured to replicate for Disaster Recovery scenarios.
- A secondary site performs different type of synchronizations against the primary site, using a special
authorization protected by JWT:
- Repositories are cloned/updated via Git over HTTPS.
- Attachments, LFS objects, and other files are downloaded via HTTPS using a private API endpoint.
From the perspective of a user performing Git operations:
- The primary site behaves as a full read-write GitLab instance.
- Secondary sites are read-only but proxy Git push operations to the primary site. This makes secondary sites appear to support push operations themselves.
To simplify the diagram, some necessary components are omitted.
- Git over SSH requires
gitlab-shelland OpenSSH. - Git over HTTPS required
gitlab-workhorse.
A secondary site needs two different PostgreSQL databases:
- A read-only database instance that streams data from the main GitLab database.
- Another database instance used internally by the secondary site to record what data has been replicated.
In secondary sites, there is an additional daemon: Geo Log Cursor.
Requirements for running Geo
The following are required to run Geo:
- An operating system that supports OpenSSH 6.9 or later (needed for fast lookup of authorized SSH keys in the database) The following operating systems are known to ship with a current version of OpenSSH:
- PostgreSQL 12 or 13 with Streaming Replication
- Note,PostgreSQL 12 is deprecated and will be removed in GitLab 16.0.
- Git 2.9 or later
- Git-lfs 2.4.2 or later on the user side when using LFS
- All sites must run the same GitLab and PostgreSQL versions.
- If using different operating system versions between Geo sites, check OS locale data compatibility across Geo sites.
Additionally, check the GitLab minimum requirements, and we recommend you use the latest version of GitLab for a better experience.
Firewall rules
The following table lists basic ports that must be open between the primary and secondary sites for Geo. To simplify failovers, we recommend opening ports in both directions.
| Source site | Source port | Destination site | Destination port | Protocol |
|---|---|---|---|---|
| Primary | Any | Secondary | 80 | TCP (HTTP) |
| Primary | Any | Secondary | 443 | TCP (HTTPS) |
| Secondary | Any | Primary | 80 | TCP (HTTP) |
| Secondary | Any | Primary | 443 | TCP (HTTPS) |
| Secondary | Any | Primary | 5432 | TCP |
See the full list of ports used by GitLab in Package defaults
NOTE:
Web terminal support requires your load balancer to correctly handle WebSocket connections.
When using HTTP or HTTPS proxying, your load balancer must be configured to pass through the Connection and Upgrade hop-by-hop headers. See the web terminal integration guide for more details.
NOTE: When using HTTPS protocol for port 443, you must add an SSL certificate to the load balancers. If you wish to terminate SSL at the GitLab application server instead, use TCP protocol.
Internal URL
HTTP requests from any Geo secondary site to the primary Geo site use the Internal URL of the primary Geo site. If this is not explicitly defined in the primary Geo site settings in the Admin Area, the public URL of the primary site is used.
To update the internal URL of the primary Geo site:
- On the top bar, select Main menu > Admin > Geo > Sites.
- Select Edit on the primary site.
- Change the Internal URL, then select Save changes.
LDAP
We recommend that if you use LDAP on your primary site, you also set up secondary LDAP servers on each secondary site. Otherwise, users are unable to perform Git operations over HTTP(s) on the secondary site using HTTP Basic Authentication. However, Git via SSH and personal access tokens still works.
NOTE: It is possible for all secondary sites to share an LDAP server, but additional latency can be an issue. Also, consider what LDAP server is available in a disaster recovery scenario if a secondary site is promoted to be a primary site.
Check for instructions on how to set up replication in your LDAP service. Instructions are different depending on the software or service used. For example, OpenLDAP provides these instructions.
Geo Tracking Database
The tracking database instance is used as metadata to control what needs to be updated on the disk of the local instance. For example:
- Download new assets.
- Fetch new LFS Objects.
- Fetch changes from a repository that has recently been updated.
Because the replicated database instance is read-only, we need this additional database instance for each secondary site.
Geo Log Cursor
This daemon:
- Reads a log of events replicated by the primary site to the secondary database instance.
- Updates the Geo Tracking Database instance with changes that must be executed.
When something is marked to be updated in the tracking database instance, asynchronous jobs running on the secondary site execute the required operations and update the state.
This new architecture allows GitLab to be resilient to connectivity issues between the sites. It doesn't matter how long the secondary site is disconnected from the primary site as it is able to replay all the events in the correct order and become synchronized with the primary site again.
Limitations
WARNING: This list of limitations only reflects the latest version of GitLab. If you are using an older version, extra limitations may be in place.
- Pushing directly to a secondary site redirects (for HTTP) or proxies (for SSH) the request to the primary site instead of handling it directly, except when using Git over HTTP with credentials embedded in the URI. For example,
https://user:password@secondary.tld. - The primary site has to be online for OAuth login to happen. Existing sessions and Git are not affected. Support for the secondary site to use an OAuth provider independent from the primary is being planned.
- The installation takes multiple manual steps that together can take about an hour depending on circumstances. Consider using the GitLab Environment Toolkit to deploy and operate production GitLab instances based on our Reference Architectures, including automation of common daily tasks. We are planning to improve Geo's installation even further.
- Real-time updates of issues/merge requests (for example, via long polling) doesn't work on the secondary site.
- GitLab Runners cannot register with a secondary site. Support for this is planned for the future.
- Selective synchronization only limits what repositories and files are replicated. The entire PostgreSQL data is still replicated. Selective synchronization is not built to accommodate compliance / export control use cases.
- Pages access control doesn't work on secondaries. See GitLab issue #9336 for details.
- GitLab chart with Geo does not support Unified URLs. See GitLab issue #3522 for more details.
Limitations on replication/verification
There is a complete list of all GitLab data types and existing support for replication and verification.
View replication data on the primary site
If you try to view replication data on the primary site, you receive a warning that this may be inconsistent:
Viewing projects and designs data from a primary site is not possible when using a unified URL. Visit the secondary site directly.
The only way to view projects replication data for a particular secondary site is to visit that secondary site directly. For example, https://<IP of your secondary site>/admin/geo/replication/projects.
An epic exists to fix this limitation.
The only way to view designs replication data for a particular secondary site is to visit that secondary site directly. For example, https://<IP of your secondary site>/admin/geo/replication/designs.
An epic exists to fix this limitation.
Setup instructions
For setup instructions, see Setting up Geo.
Post-installation documentation
After installing GitLab on the secondary sites and performing the initial configuration, see the following documentation for post-installation information.
Configuring Geo
For information on configuring Geo, see Geo configuration.
Upgrading Geo
For information on how to update your Geo sites to the latest GitLab version, see Upgrading the Geo sites.
Pausing and resuming replication
Introduced in GitLab 13.2.
WARNING: In GitLab 13.2 and 13.3, promoting a secondary site to a primary while the secondary is paused fails. Do not pause replication before promoting a secondary. If the site is paused, be sure to resume before promoting. This issue has been fixed in GitLab 13.4 and later.
WARNING: Pausing and resuming of replication is only supported for Geo installations using an Omnibus GitLab-managed database. External databases are not supported.
In some circumstances, like during upgrades or a planned failover, it is desirable to pause replication between the primary and secondary.
Pausing and resuming replication is done via a command line tool from the node in the secondary site where the postgresql service is enabled.
If postgresql is on a standalone database node, ensure that gitlab.rb on that node contains the configuration line gitlab_rails['geo_node_name'] = 'node_name', where node_name is the same as the geo_name_name on the application node.
To Pause: (from secondary)
gitlab-ctl geo-replication-pauseTo Resume: (from secondary)
gitlab-ctl geo-replication-resumeConfiguring Geo for multiple nodes
For information on configuring Geo for multiple nodes, see Geo for multiple servers.
Configuring Geo with Object Storage
For information on configuring Geo with object storage, see Geo with Object storage.
Disaster Recovery
For information on using Geo in disaster recovery situations to mitigate data-loss and restore services, see Disaster Recovery.
Replicating the Container Registry
For more information on how to replicate the Container Registry, see Container Registry for a secondary site.
Geo secondary proxy
For more information on using Geo proxying on secondary sites, see Geo proxying for secondary sites.
Security Review
For more information on Geo security, see Geo security review.
Tuning Geo
For more information on tuning Geo, see Tuning Geo.
Set up a location-aware Git URL
For an example of how to set up a location-aware Git remote URL with AWS Route53, see Location-aware Git remote URL with AWS Route53.
Backfill
Once a secondary site is set up, it starts replicating missing data from the primary site in a process known as backfill. You can monitor the synchronization process on each Geo site from the primary site's Geo Nodes dashboard in your browser.
Failures that happen during a backfill are scheduled to be retried at the end of the backfill.
Remove Geo site
For more information on removing a Geo site, see Removing secondary Geo sites.
Disable Geo
To find out how to disable Geo, see Disabling Geo.
Frequently Asked Questions
For answers to common questions, see the Geo FAQ.
Log files
Geo stores structured log messages in a geo.log file. For Omnibus GitLab
installations, this file is at /var/log/gitlab/gitlab-rails/geo.log.
This file contains information about when Geo attempts to sync repositories and files. Each line in the file contains a separate JSON entry that can be ingested into. For example, Elasticsearch or Splunk.
For example:
{"severity":"INFO","time":"2017-08-06T05:40:16.104Z","message":"Repository update","project_id":1,"source":"repository","resync_repository":true,"resync_wiki":true,"class":"Gitlab::Geo::LogCursor::Daemon","cursor_delay_s":0.038}This message shows that Geo detected that a repository update was needed for project 1.
Troubleshooting
For troubleshooting steps, see Geo Troubleshooting.