Two of four parts nearly finished
Showing
+2989 -0
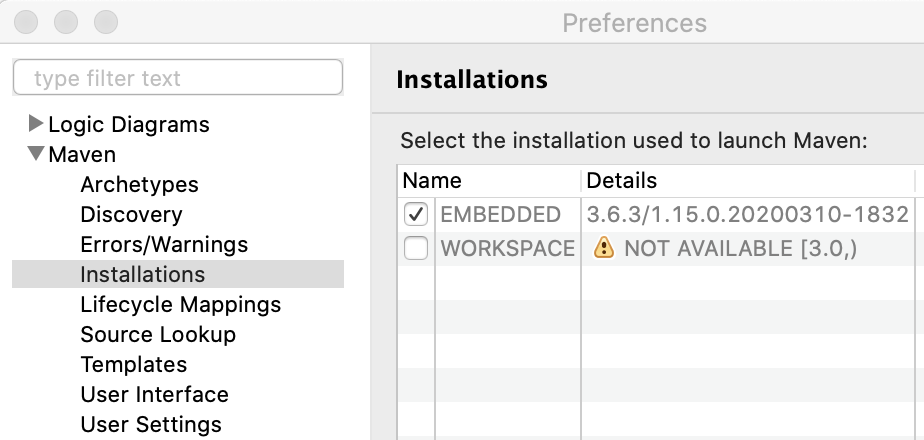
Images/InstallMaven3.gif
0 → 100644
+ 0
- 0
{kind=link}
77.4 KB
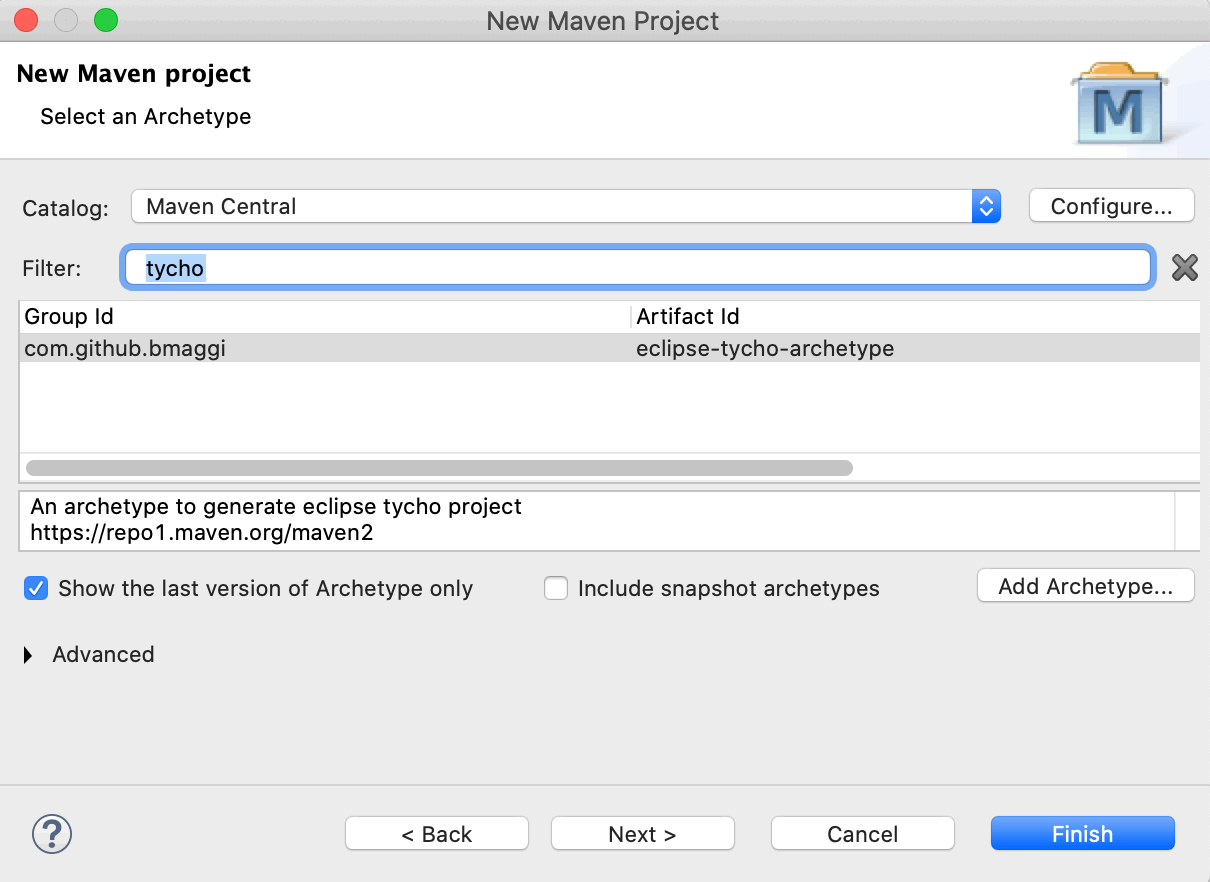
Images/NewTychoProject1.gif
0 → 100644
+ 0
- 0
{kind=link}
47.5 KB
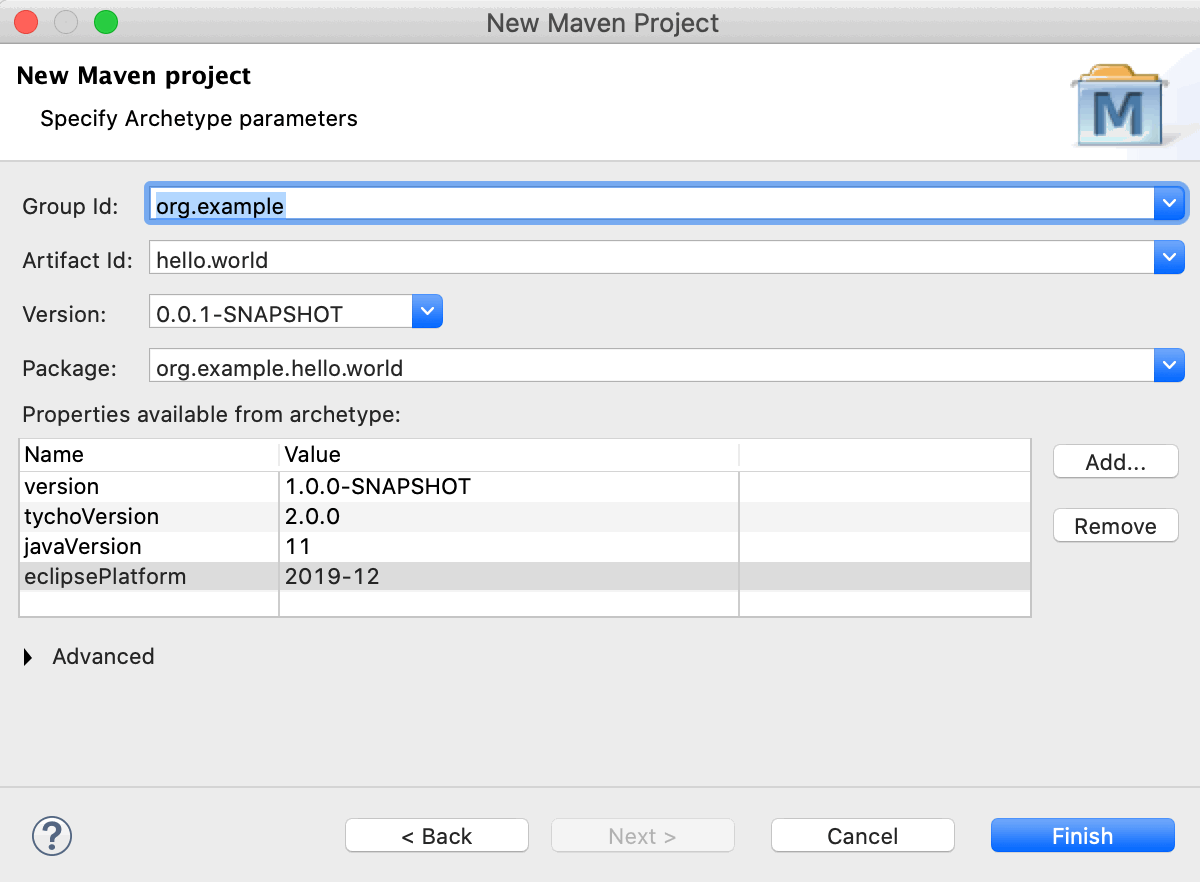
Images/NewTychoProject2.gif
0 → 100644
+ 0
- 0
{kind=link}
47.5 KB
+ 0
- 0
{kind=link}
199 KB
+ 0
- 0
{kind=link}
118 KB
LICENSE.html
0 → 100644
ParameterCatalogs.adoc
0 → 100644
ParameterCatalogs.html
0 → 100644
This diff is collapsed.
ParameterCatalogs.pdf
0 → 100644
+ 0
- 0
File added
ParameterCatalogs1Overview.adoc
0 → 100644
ParameterCatalogs2Creation.adoc
0 → 100644
This diff is collapsed.
ParameterCatalogs2Images/ButtonLinkPlus.gif
0 → 100644
+ 0
- 0
{kind=link}

1.11 KB
+ 0
- 0
{kind=link}
627 KB
ParameterCatalogs2Images/EclipseDownload.gif
0 → 100644
+ 0
- 0
{kind=link}

55.9 KB
+ 0
- 0
{kind=link}

51.3 KB
ParameterCatalogs2Images/EcoreClassifier.png
0 → 100644
+ 0
- 0
{kind=link}
31.5 KB
ParameterCatalogs2Images/EcoreRelations.gif
0 → 100644
+ 0
- 0
{kind=link}

7.54 KB
ParameterCatalogs2Images/GenerateMenu.png
0 → 100644
+ 0
- 0
{kind=link}
175 KB
+ 0
- 0
{kind=link}
202 KB
ParameterCatalogs2Images/Homework.gif
0 → 100644
+ 0
- 0
{kind=link}
68.1 KB